行学AI使用指南-你的学术科研AI助手!学术GPT
一、行学AI是什么?
行学AI(原名智增增sci),你的学术科研AI助手!学术GPT。基于最强大的chatgpt-4.0大模型打造的学术GPT,为学术科研助力。
目前仅支持在pc端使用,持续优化ing
名字源自:《礼记·中庸》博学之,审问之,慎思之,明辨之,笃行之。
二、行学AI系列教程、文章和视频
包括行学AI系列教程、文章和视频,访问地址:https://work.zhizengzeng.com/1877.html
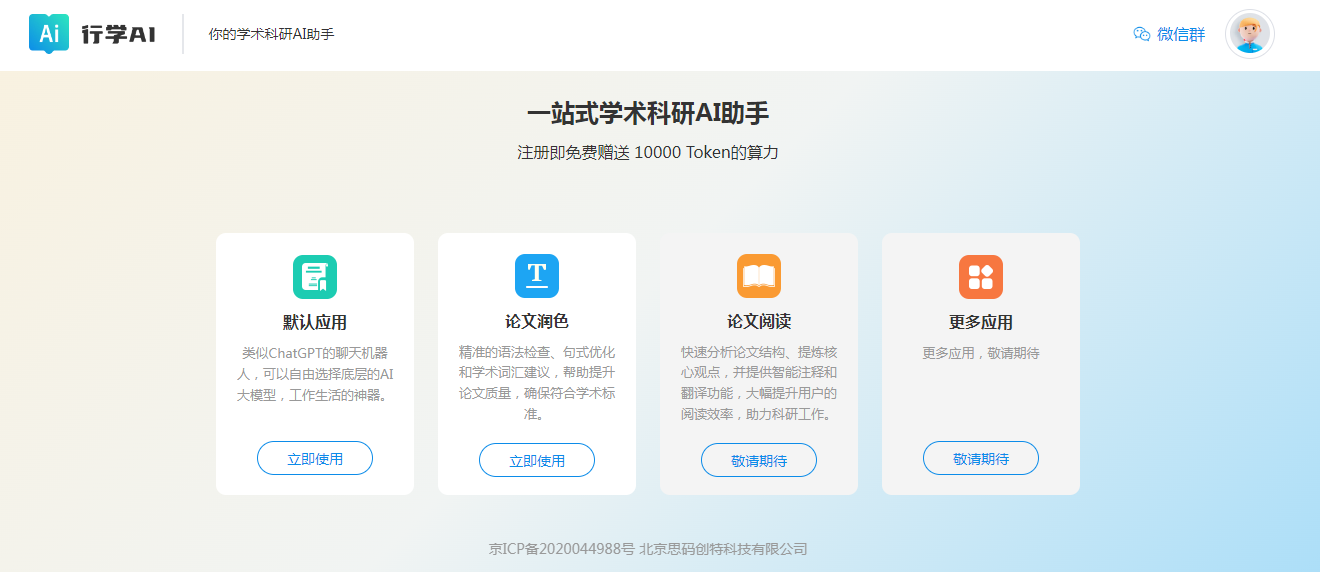
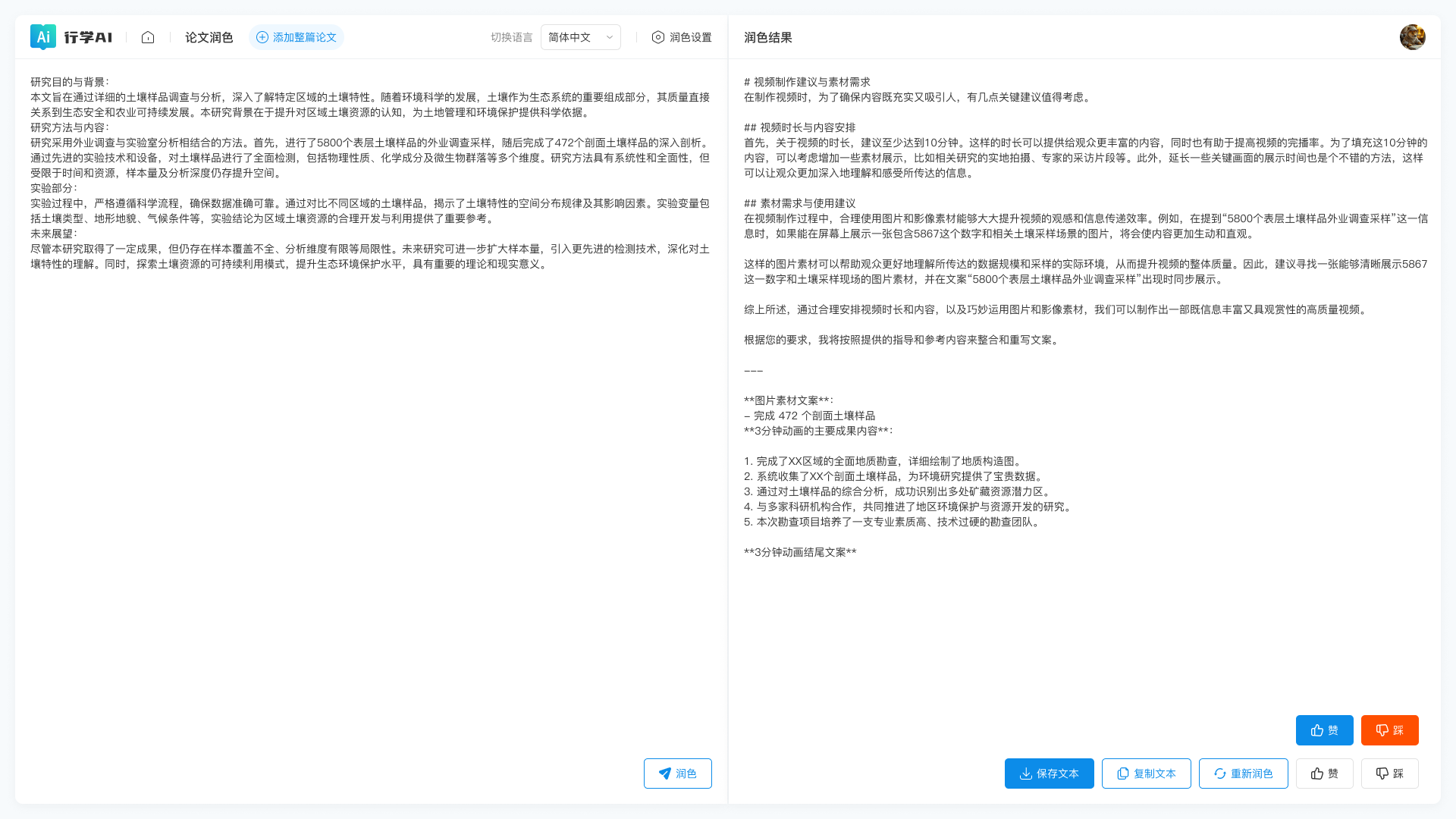
三、功能示意和截图
- 支持论文润色、论文翻译、论文阅读等
- 支持论文阅读理解、论文里面的细节探讨、国内大模型、ChatGPT3.5和ChatGPT4.0等强力加持的大模型,让AI助手真正能助力学术科研人员更好的掌握学术论文
- 注册即拥有免费额度
- 更多重磅功能,敬请期待。
使用截图:
四、常见问题解答
问:行学AI的底层原理是什么?
问:token是什么?
以句子“The quick brown fox jumps over the lazy dog”为例,如果将其分解为单词级别的token,则包含的token有:“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”。如果采用子词级别的token化,则可能会将某些单词进一步拆分,如将“jumps”拆分为“jump”和“s”。
问:不同的AI大模型的token是怎么定价的?
| token价格说明表格: | |||
|---|---|---|---|
|
模型名称
|
供应商
|
api token价格
|
模型说明
|
| AI-4o-mini模型-经济实惠 | OpenAI | 输入:$0.00015 / 1K tokens
输出:$0.0006 / 1K tokens |
GPT-4o mini,更好用更便宜的 GPT。GPT-4o mini 不仅性能更强,价格也来到了「白菜价」。具体来讲,GPT-4o mini 每百万个输入 Token 的定价是 15 美分(约合人民币 1.09 元),每百万个输出 Token 的定价是 60 美分(约合人民币 4.36 元) |
| AI-4o模型-最强大模型 | OpenAI | 输入:$0.005 / 1K tokens
输出:$0.015 / 1K tokens |
GPT-4o的名称中“o”代表Omni,即全能的意思,凸显了其多功能的特性。GPT-4o在处理速度上提升了高达200%,同时在价格上也实现了50%的下降,GPT-4o所有功能包括视觉、联网、记忆、执行代码以及GPT Store等 |
| 百度文心一言.ERNIE-4.0-8K | 百度 | 输入:¥0.12 /1k tokens
输出:¥0.12 /1k tokens |
ERNIE 4.0是百度自研的旗舰级大模型 |
| 百度文心一言.ERNIE-3.5-8K | 百度 | 输入:¥0.008 /1k tokens
输出:¥0.008 /1k tokens |
百度自研的大模型3.5 |
| 百度文心一言.ERNIE-Speed-128K | 百度 | ¥0 /1k tokens(免费) | 百度文心一言模型。 免费使用,不收费啊不收费。 |
| 谷歌.gemini-1.5-pro | 谷歌 | 输入:$0.008 /1k tokens
输出:$0.024 /1k tokens |
谷歌最新模型,提供更复杂的语言理解和生成能力。 |
| 谷歌.gemini-1.5-flash | 谷歌 | 输入:$0.008 /1k tokens
输出:$0.024 /1k tokens |
谷歌大模型 |
| Anthropic.claude-3-5-sonnet-20240620 | Anthropic | 输入:$0.003 /1k tokens
输出:$0.015 /1k tokens |
Claude模型的最新版本, Claude 3.5 Sonnet |
| Anthropic.claude-3-haiku-20240307 | Anthropic | 输入:$0.00025 /1k tokens
输出:$0.00125 /1k tokens |
Claude模型 |
| 字节跳动.Doubao-lite-4k | 字节跳动 | 输入:¥0.0003/1k tokens
输出:¥0.0006/1k tokens |
字节跳动豆包大模型。 |
| 字节跳动.Doubao-lite-32k | 字节跳动 | 输入:¥0.0003/1k tokens
输出:¥0.0006/1k tokens |
字节跳动豆包大模型。 |
| 字节跳动.Doubao-lite-128k | 字节跳动 | 输入:¥0.0008/1k tokens
输出:¥0.001/1k tokens |
字节跳动豆包大模型。 |
| 字节跳动.Doubao-pro-4k | 字节跳动 | 输入:¥0.0008/1k tokens
输出:¥0.002/1k tokens |
字节跳动豆包大模型。 |
| 字节跳动.Doubao-pro-32k | 字节跳动 | 输入:¥0.0008/1k tokens
输出:¥0.002/1k tokens |
字节跳动豆包大模型。 |
| 字节跳动.Doubao-pro-128k | 字节跳动 | 输入:¥0.005/1k tokens
输出:¥0.009/1k tokens |
字节跳动豆包大模型。 |
| 腾讯混元.hunyuan-pro | 腾讯 | 输入:¥0.03 /1k tokens
输出:¥0.1 /1k tokens |
腾讯混元大模型。 |
| 腾讯混元.hunyuan-standard | 腾讯 | 输入:¥0.0045 /1k tokens
输出:¥0.005 /1k tokens |
腾讯混元大模型。 |
| 腾讯混元.hunyuan-standard-256k | 腾讯 | 输入:¥0.015 /1k tokens
输出:¥0.06 /1k tokens |
腾讯混元大模型。 |
| 腾讯混元.hunyuan-lite | 腾讯 | ¥0 /1k tokens(免费) | 腾讯混元大模型。 |
| 阿里通义千问.qwen-max | 阿里 | 输入:¥0.04 /1k tokens
输出:¥0.12 /1k tokens |
阿里通义千问模型。 |
| 阿里通义千问.qwen-plus | 阿里 | 输入:¥0.004 /1k tokens
输出:¥0.012 /1k tokens |
阿里通义千问模型。 |
| 阿里通义千问.qwen-turbo | 阿里 | 输入:¥0.002 /1k tokens
输出:¥0.006 /1k tokens |
阿里通义千问模型。 |
| 讯飞星火.SparkDesk | 讯飞 | 输入:¥0.03 /1k tokens
输出:¥0.03 /1k tokens |
讯飞星火大模型,指向最新的版本。 |
| 讯飞星火.SparkDesk-v1.1 | 讯飞 | ¥0 /1k tokens(免费) | 讯飞星火大模型。Spark Lite。 完全免费,不收费啊不收费 |
| 百川智能.Baichuan4 | 百川智能 | 输入:¥0.1 /1k tokens
输出:¥0.1 /1k tokens |
百川智能大模型。 |
| 百川智能.Baichuan3-Turbo | 百川智能 | 输入:¥0.012 /1k tokens
输出:¥0.012 /1k tokens |
百川智能大模型。 |
| 月之暗面.moonshot-v1-8k | 月之暗面 | 输入:¥0.012 /1k tokens
输出:¥0.012 /1k tokens |
月之暗面模型。 |
| 月之暗面.moonshot-v1-32k | 月之暗面 | 输入:¥0.024 /1k tokens
输出:¥0.024 /1k tokens |
月之暗面模型。 |
| 月之暗面.moonshot-v1-128k | 月之暗面 | 输入:¥0.060 /1k tokens
输出:¥0.060 /1k tokens |
月之暗面模型。 |
| 智谱清言.glm-4-long | 智谱 | 输入:¥0.001 /1k tokens
输出:¥0.001 /1k tokens |
智谱清言模型。 |
| 智谱清言.glm-4-flash | 智谱 | 输入:¥0.0001 /1k tokens
输出:¥0.0001 /1k tokens |
智谱清言模型。 |
| 深度求索.deepseek-chat | 深度求索 | 输入:1 元 / 百万 tokens
输出:1 元 / 百万 tokens |
深度求索模型。 |
| 零一万物.yi-large | 零一万物 | 输入:20 元 / 百万 tokens
输出:20 元 / 百万 tokens |
零一万物大模型。 |
| 零一万物.yi-medium | 零一万物 | 输入:2.5 元 / 百万 tokens
输出:2.5 元 / 百万 tokens |
零一万物大模型。 |
问:还是有疑问怎么办?

相关文章
